
Introduction
Flipkart is the biggest E-Commerce site based in India. Flipkart is recently gathered by Walmart, is known as one of the biggest retail companies all over the world. S&P Global had shared a report in 2018, Flipkart was having the packed with 31.9% of the market share wherein Amazon close on 31.2%. Standing on top of the world of retailers, Flipkart is having millions of data at disposal of the web scrapers. There is some product information like a specification for all electronic things, the price details website is having all the details which need to scrape. If you testing an E-Commerce scraping tool, or if you are trying to search for e-commerce for market research either you are doing an analysis of price comparison; in this, you need to give importance and you need to take care of your crawlers so that they can get a good amount of data. Let’s discuss how Web Scraper Flipkart is done while using Python.
Web Scraper Flipkart Extractor helps to get data from one page. By this, you can make a list of websites and you can gather all the data from pages, and willbe able to do the implementation.
Web Flipkart Scraping Code
Start coding, the beautiful soup library, and there are many code editors like Wonderful, and it is just as always. Once you are ready with your setup, you can move ahead with the run code is shown below.
It is the main principle to understand every code that you need to optimize it; can be used over multiple websites, or you either change the code to scrape other E-Commerce websites. We can start importing all necessary and internal and external libraries that can ignore SSL certificate errors. We accept URL from different users, that should be for product page URL from Flipkart.
After the URL is made and storing it in a variable, we are sending HTTP GET requests and extract HTML feeds. After the step is been perform, we can read many websites and convert themtoa BeautifulSoup object. This needs to be understood that Website content can be scraped with ease and comfortless. We can prefer HTML Satisfaction and can be saved for the variable.
Now we have an HTML database in the BeautifulSoup object, we can create a different dictionary with “product details” in that we can able to store different set points that can extract from a different webpage. We can start with the first “script” and you can tag with attribute “ID” as having a value of “jsonLD”. Inside, we can find a JSON value from that we can start extract ratings, brand-name, number of reviews, and images. After that, we can easily pick all the ‘li’ tags with all attribute ’class’ set as ‘_2-riNZ’. All tag needs certain attributes of the product, which can have scraped one by one to “highlights” in ‘product_details’.
The Code is used to Scrape Data from Flipkart
Price is the main important aspect for data-point and there are many e-commerce websites that we are scrape competitor’s data frequently for the data sets. We easily get everything from the first ‘div’ tag on the webpage all the attribute ‘class’ having each valuefor‘_1vC4OE_3qQ9m1’. We can capture different descriptions stored in different descriptionsof headers. These all extract in key-value format. The descriptionheaderis mainly seen in the list of ‘div’ tags which can see all attribute ‘class’ set ‘_2THx53’. The description themselves needs to store in ‘div’ tags with all attribute ‘class’ and set as ‘_1aK10F’.
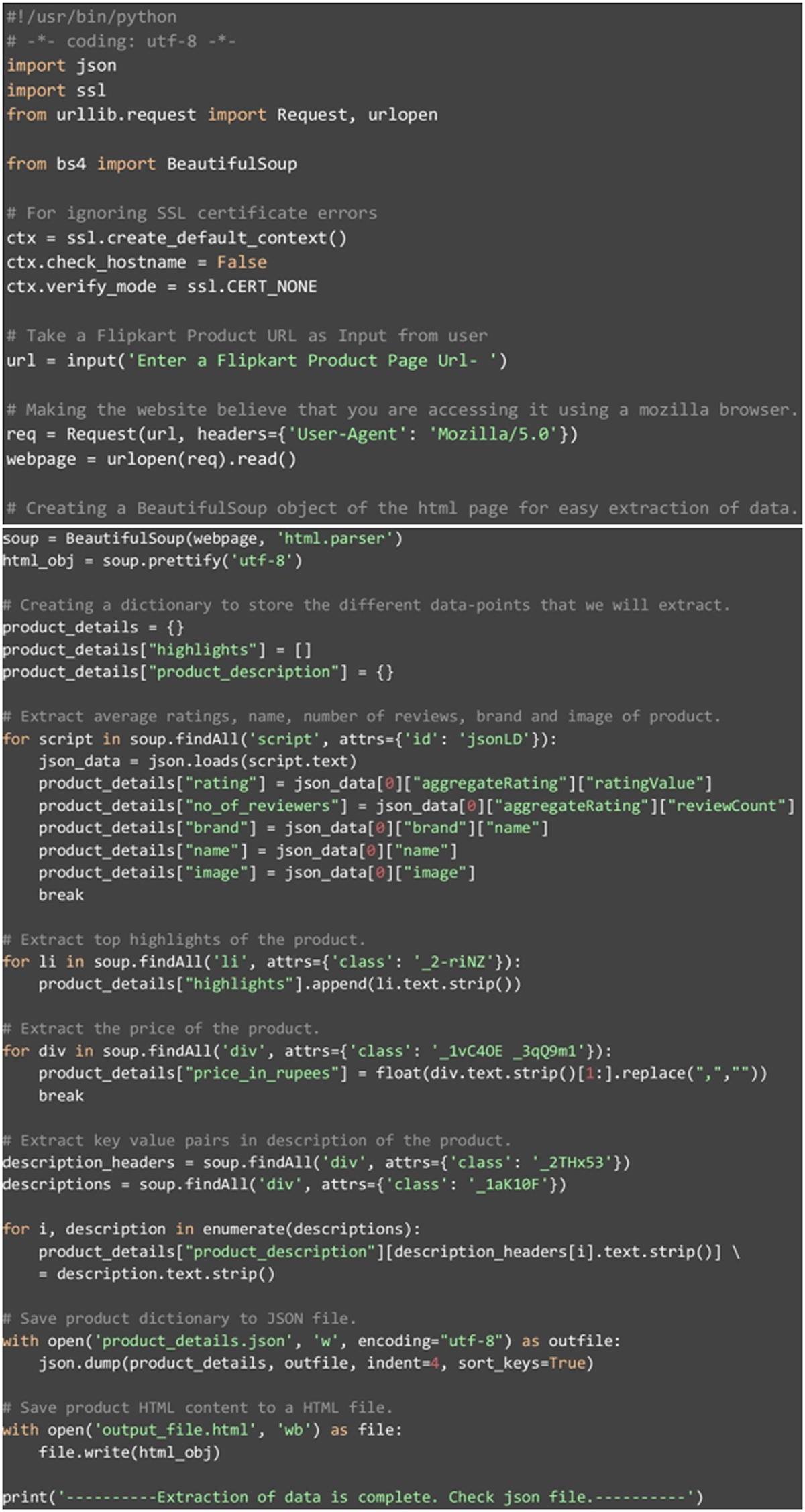
Once the data is being extracted is stored in a directory that can be created, we need to save directly to JSON file name ‘product_details. Json’. We are also saving a beautiful name like ‘output_file.html’. Required for HTML needs to be done manually and they can analyze new set-points that can need to be found. Extracting Data sets in this piece can also possible by manual analysis for the HTML.
Data We Extracted Via Web Scraping
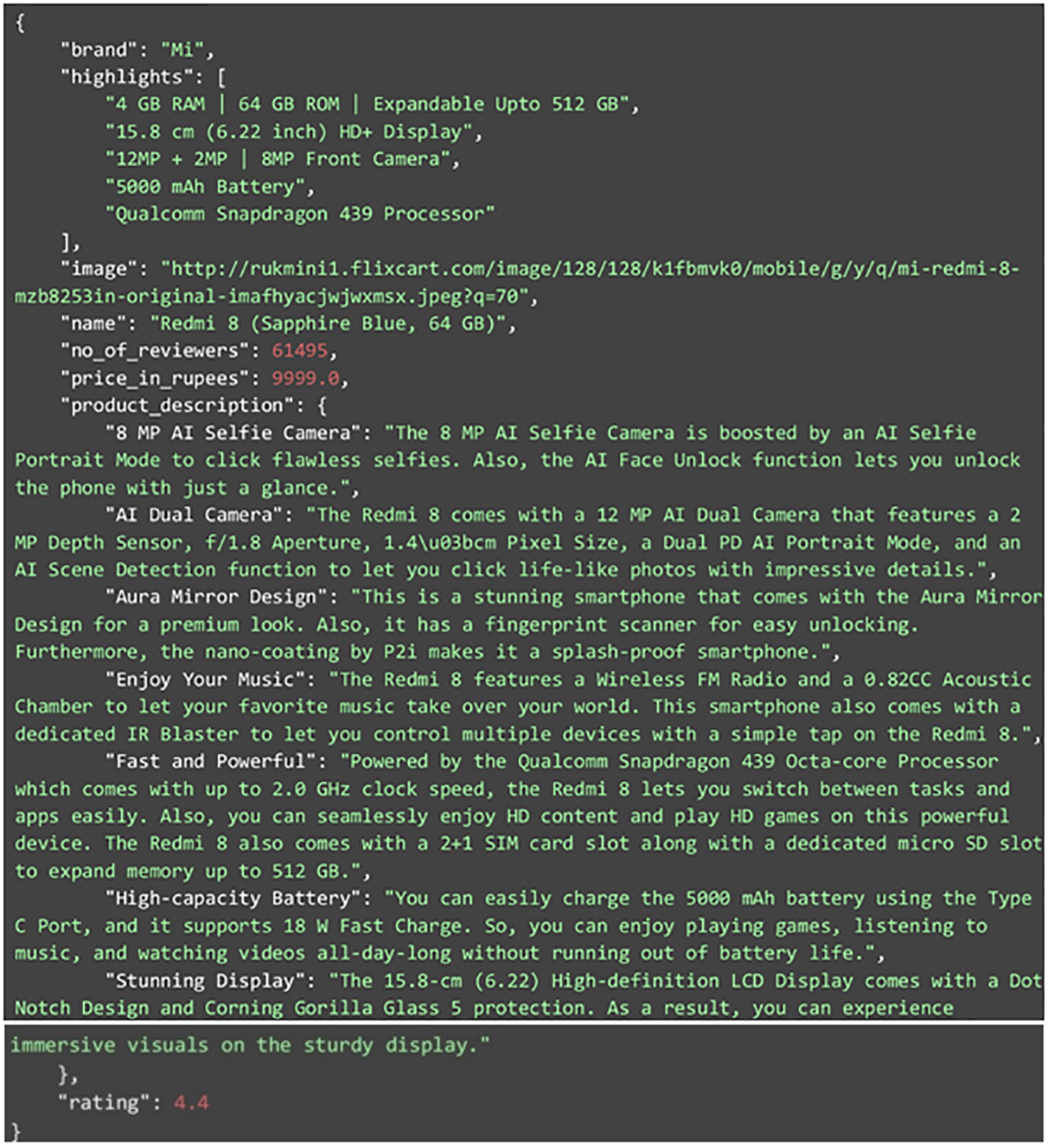
Let us look that our code needs to be run, the data that we extracted. With the product URL we are providing, this JSON below is what we got in the result. Let us analyze the deep dive into the data. Some data points have single values;we have like-
- Image
- Brand
- Number of reviewers
- Name
- Ratings
- Price in rupees
Other Datasets, can be highlighted which can create a list of details of the product. The product description contains the key value of pairs for understanding through JSON.
Constraints & More
It comes toa complete enterprise-grade solution; the piece of the code will help you to build a new one? Many problems you need to face while running code. When you need to accept the URL, in the case of input awrong URL will apply to Flipkart URL, then expectation will get bound and will be on the top. So this thing is a very important aspect to handle. If the URL is valid then not all the producthas the data-sets for extracting in the given code. In all this scenario we need to handle expectation handling. If you want to scrape thousands and millions of products from the website, then your code should run perfectly so you should do maximum use of all the systems and will able to get muchinformation every time. Such implementation isuseful for solutions that can save time and effort.
Conclusion
There is the chance for IP blocking while delivering such huge projects, and for that IP rotation in other tools that need to integrate with the system. Taking care of the legal aspects for scraping competitor’s data we need to take care of. Many options are available in the DIY solution for all these, for that needs to build your web scraping team if you have resources for DaaS provides like RetailGators.
Our team of Retailgators makes Web Scraping an easy and hustle-free solution and reduces the number of steps in the process for requirements, plugging, and submission for scraping the data. In the back of mind web scraping if injecting data into your business to a data-drive decision should not be hard. That’s the reason our solution helps companies can take steps easily.
So if you are looking for the best Web Scraping Flipkart Using Python services then you can contact Retailgators for all your quotes and queries.




Leave a Reply
Your email address will not be published. Required fields are marked